How to Scrape Reviews From Glassdoor With React
Selenium Tutorial: Scraping Glassdoor.com in 10 Minutes
I scraped jobs data from Glassdoor.com for a project. Let me tell you how I did information technology…
What is Scraping?
It's a method for collecting information from web pages.
Why Scraping?
Other than the fact that information technology is fun, Glassdoor's library provides a express number of data points. It doesn't permit you to scrape jobs or reviews. You only get to scrape companies, which was useless in my case. In this guide, I will share my way of doing it along with the Jupyter Notebook.
Why Selenium?
Expert question! Glassdoor renders its content with Javascript. Which ways that a simple get request to the webpage beneath would render only the visible content. We are interested in more than that.
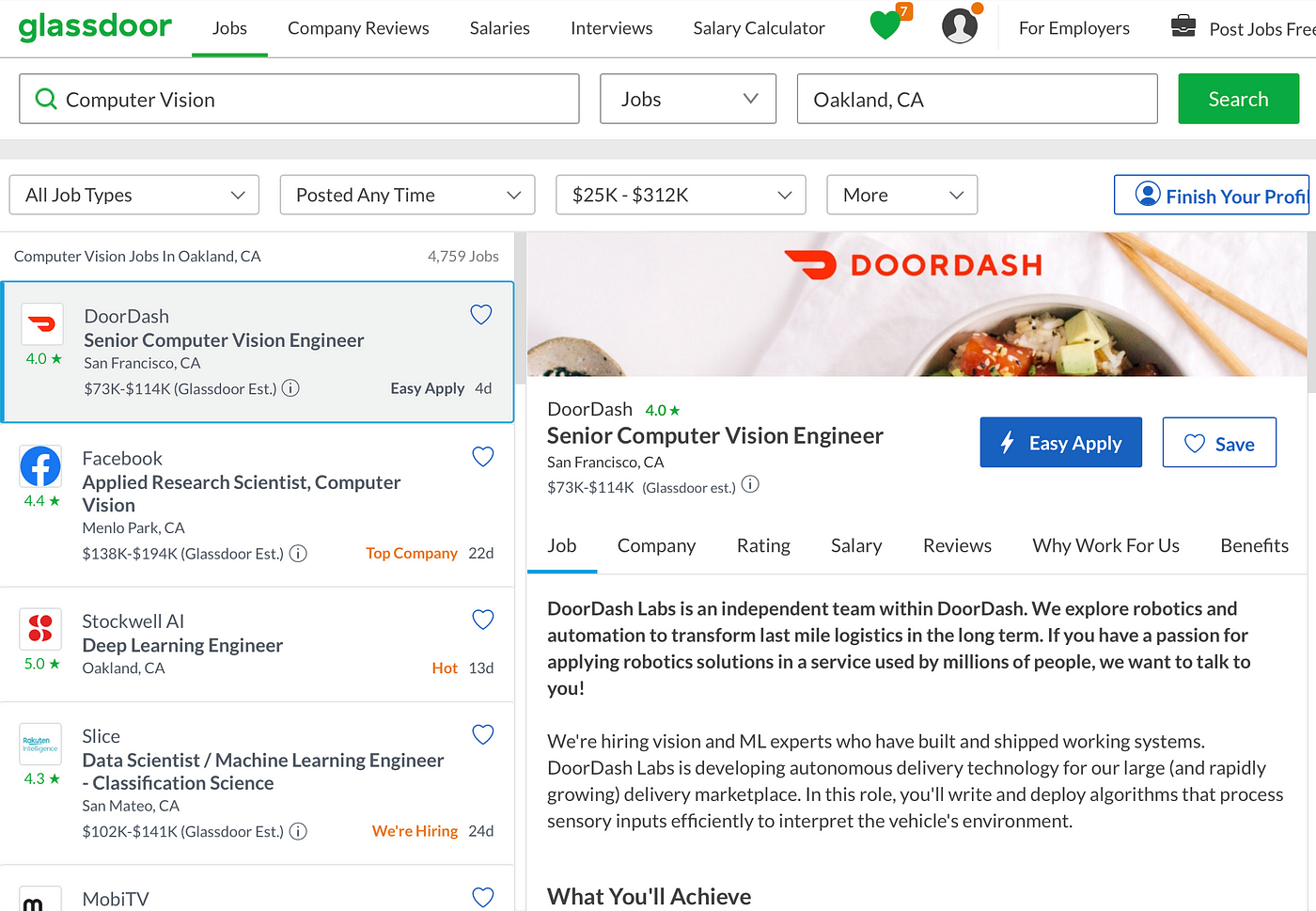
There are data points such as company valuation and chore location under the "Company" tab and we desire to access that information as well. The webpage does not evidence that content unless the user clicks on the "Company" tab. This makes clicking on the "Company" tab necessary. Using requests library and doing simple go requests would not work for this type of website. Therefore, the merely way to scrape that information is to write a program that mimics a human user. Selenium is a library that lets you lawmaking a python script that would act simply like a human user.
What nosotros will build?
Substantially nosotros will exist building a python script that would requite u.s.a. a DataFrame like this:
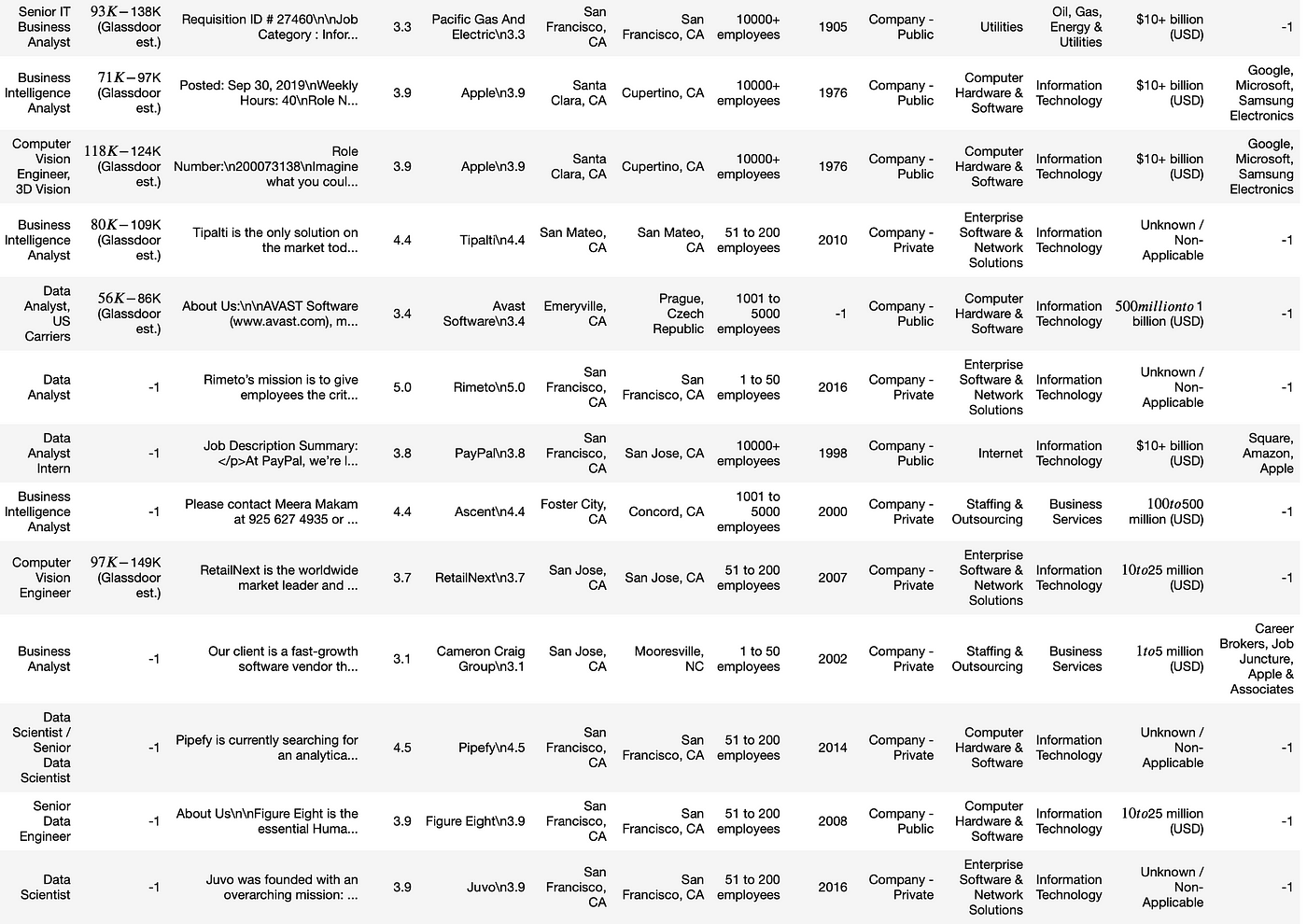
The python script will exactly do the following. Search for a given keyword, click on each job all on the task listings all the way downwardly, click on dissimilar tabs in the job description panel, scrape all the data. When information technology reaches the end of the list, it will go to the adjacent folio of results and go along doing the same thing, until a target number of jobs scraped. The last result volition simulate Google chrome similar the following. Everything is automated, no human interaction involved below.
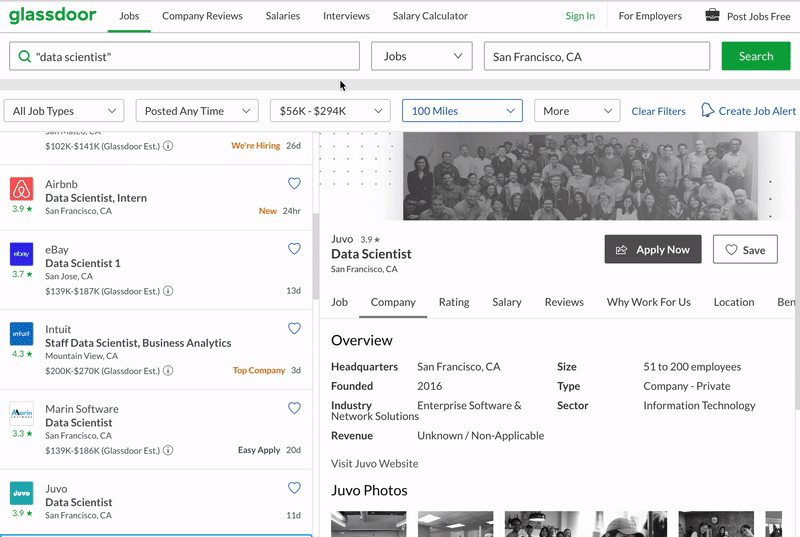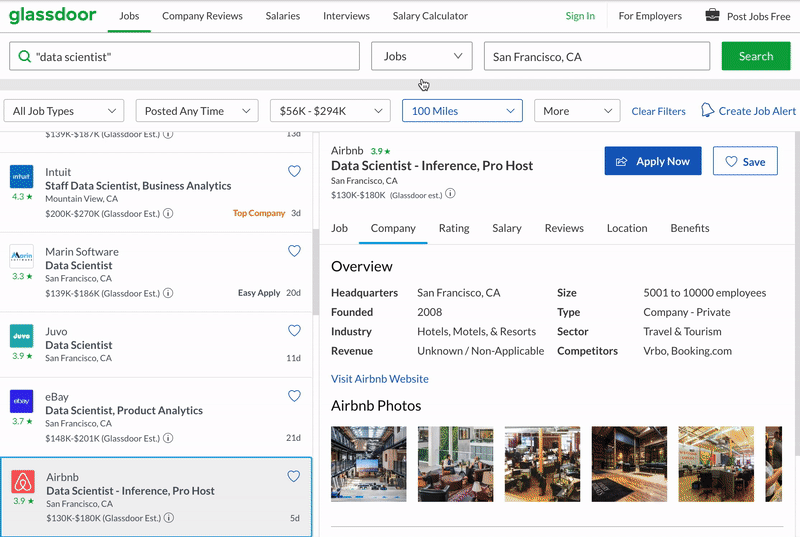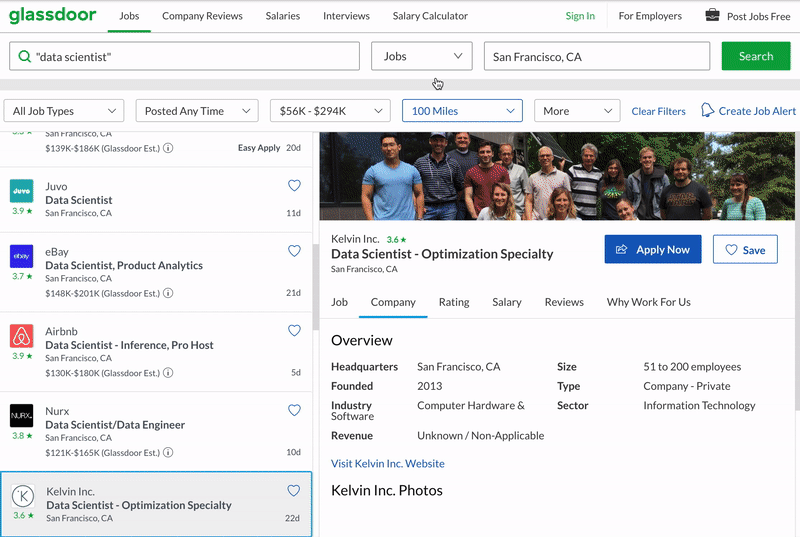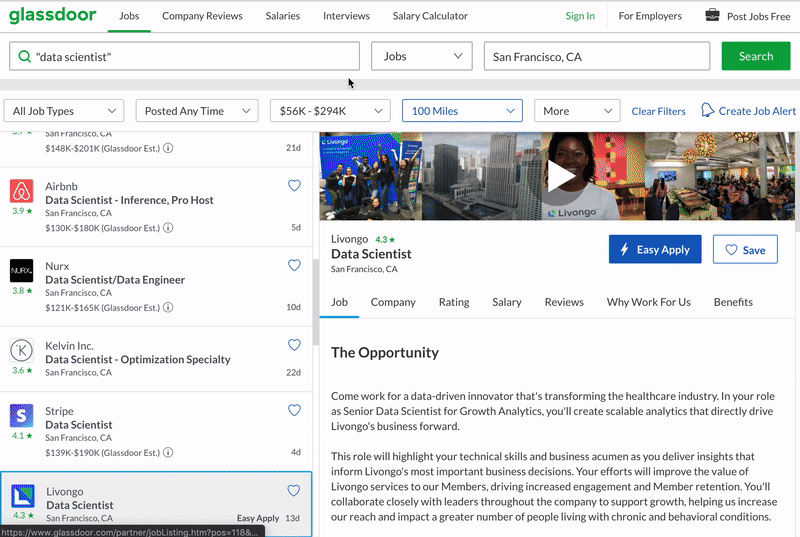
Pre-requisites
- Working knowledge of python
- python version 3.ten
- Jupyter notebook installed
- Very basic knowledge of html
- Some knowledge of XPath would besides go a long fashion.
- selenium library installed
- ChromeDriver placed on a directory you lot know.
The Core Principle of Web Scraping
It is quite uncomplicated. Let's assume you take an eye on some spider web page element (such equally text) and would like to scrape it. Elements on a spider web folio reside in a hierarchy. You just need to tell your lawmaking the "address" of the element within that hierarchy.
Permit's have the headquarters information of a company equally an element of interest. In the picture below, the headquarters of this company is San Francisco, CA. Therefore, we should scrape "San Francisco, CA". All you need to do is, right-click and "Inspect Element". That volition open a small window with the html content of the spider web page, with your chemical element highlighted for y'all. Y'all also encounter where the elements are placed in the hierarchy.

You can non meet the rest of the hierarchy in the picture but it does not really matter anyway. Because we will utilize relative address in order to explain where the element is. We are going to say, look for a div, with a class of "infoEntity" that has a label equally a child, which has "Headquarters" as text, and take the text within the following sibling of it. We are just going to say it in a formal fashion. The XPath below does just that. We do not have to mention the whole hierarchy because chances are, this description fits but this html element.

#Also putting the code in text form in example you lot'd like to copy and paste. try:
headquarters = driver.find_element_by_xpath('.//div[@class="infoEntity"]//characterization[text()="Headquarters"]//following-sibling::*').text
except NoSuchElementException:
headquarters = -1
If you understand what we're doing here, it means that you can easily scrape almost any webpage you'd like. Nosotros are basically describing the long, awkward sentence in the paragraph above in a formal way. Feel gratuitous to take a deeper look into XPath if yous'd similar.
Also, notice that nosotros have put the statement within a effort-catch clause. This is skillful practice if yous are scraping spider web elements since they might non even exist. For glassdoor'southward example, non all fields are always available. A company might non have put up their headquarters to glassdoor. If that'due south the instance, for the data fields, yous might desire to assign a "not establish" value. I have called -one for that purpose.
The Code
You lot can download the Jupyter notebook hither . If you lot were able to understand what we did above and have a basic knowledge of python, you should be able to read the code with comments. For the remainder of this post, I will explain fiddling tricks in the code that are not so obvious why.
Note that you need to change the path to the chromedriver and so that it points to the chromedriver in your local file system.
Bypassing the Sign-Up Prompt
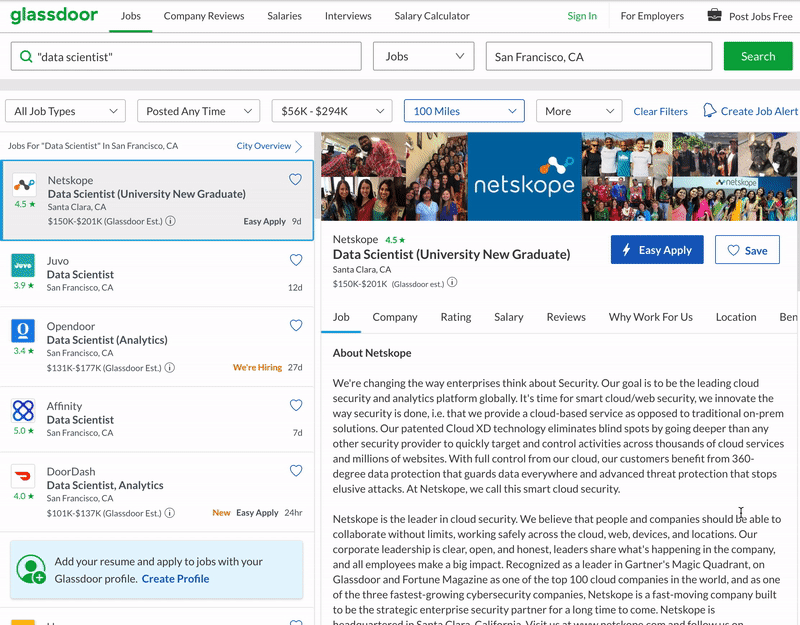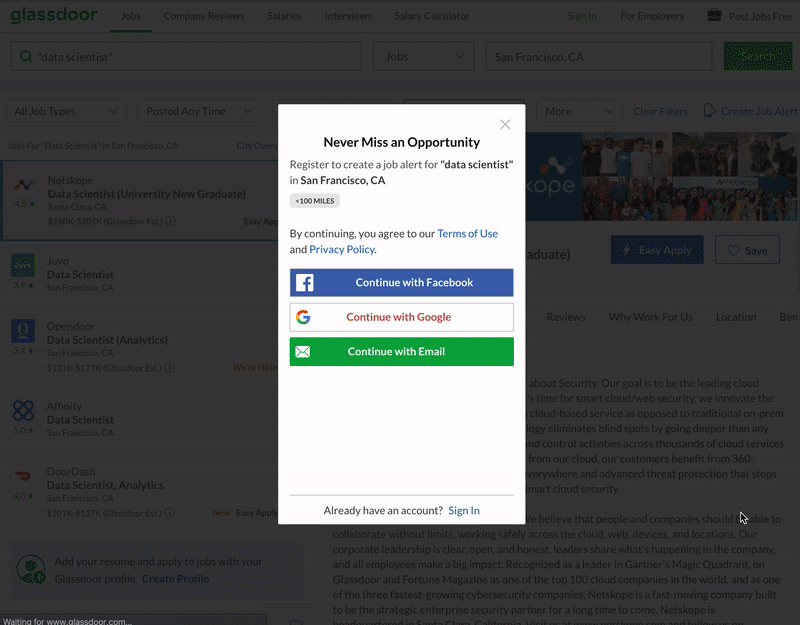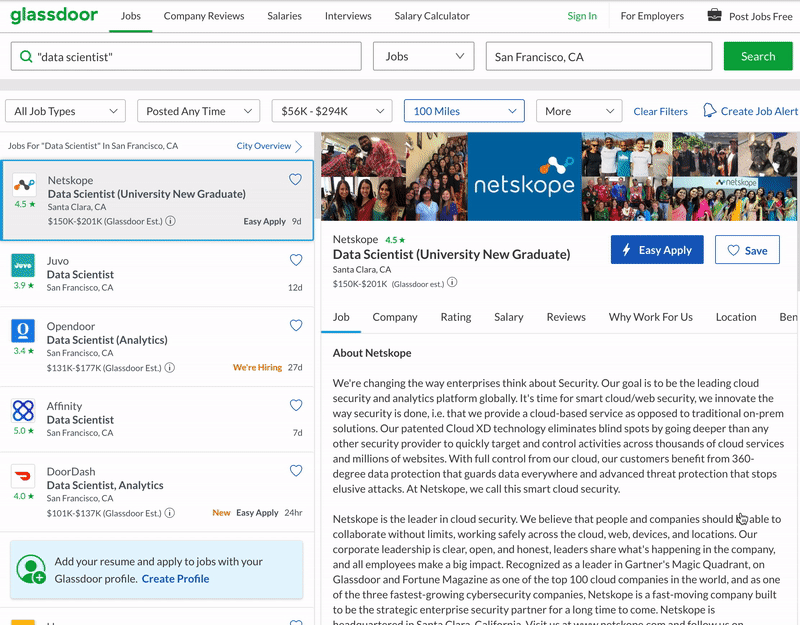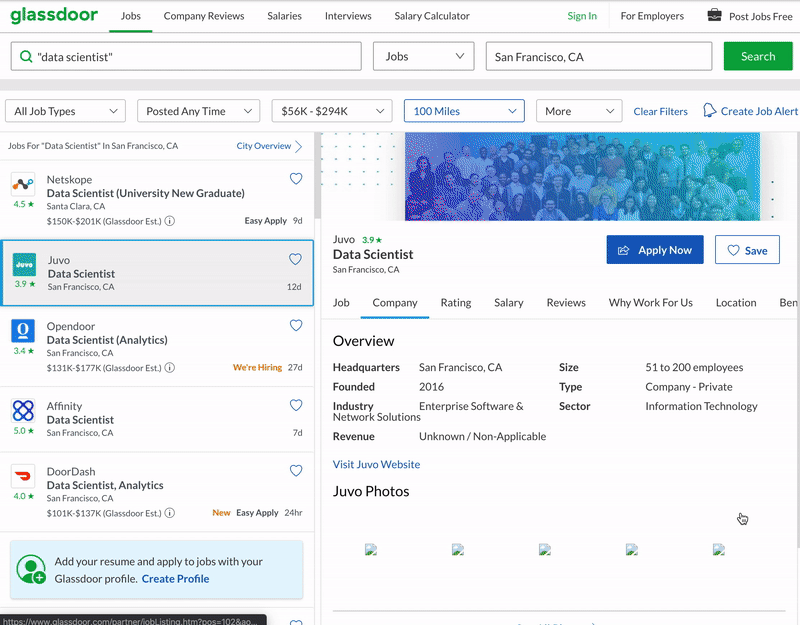
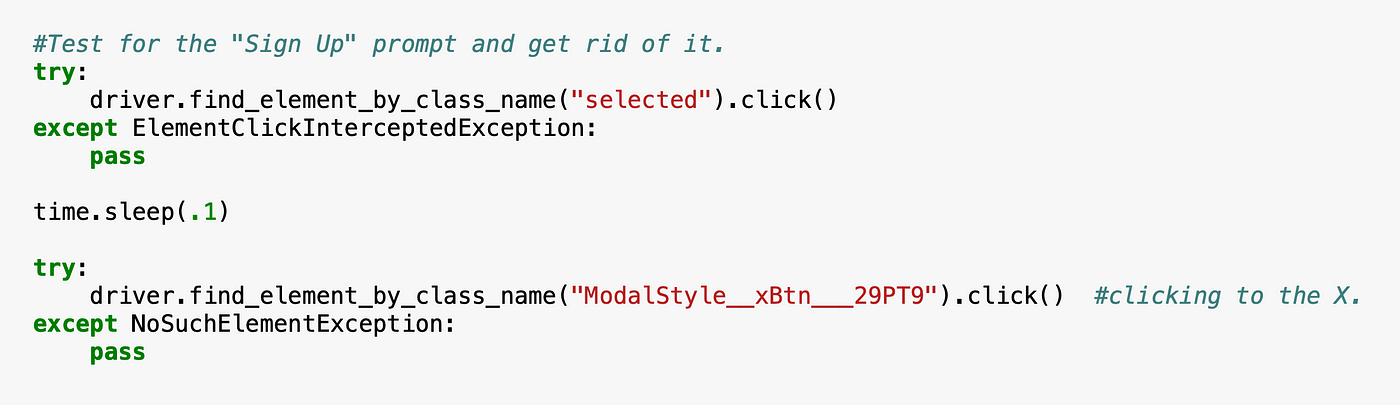
One challenge scraping the glassdoor was that if you accept not signed upwards, which in our case you won't, as presently every bit you click anywhere on the screen, it asks you to sign upwardly. A new window comes up and blocks selenium from clicking anywhere else. This is the case every fourth dimension selenium does a new search or go to the side by side page of chore listings. The manner nosotros are dealing with this is that nosotros click the 10 button to shut information technology correct after clicking on an capricious task posting on the website. In the lawmaking, the arbitrary chore is the topmost job listing. Information technology comes selected equally default. Therefore that element's class name is "selected". Nosotros can find and click on it by find_element_by_class_name("selected").
How Nearly Glassdoor API?
Equally of today, Glassdoor does not take whatever public API for Jobs. Which means that you accept to do scraping if you want to get data nearly job posting. I heard yous maxim cheers. Yous are welcome.
Also, Glassdoor does not have an API for reviews either, which might be of involvement to you. I would recommend this tutorial in example you would like to obtain reviews.
Getting rejected or throttled past Glassdoor
Ane other point about Glassdoor's website is that, if you become also aggressive about get requests, Glassdoor will first rejecting or throttling your connections. In other words, if you were to exercise a get asking to multiple links at once, it is probable that your IP accost will go blocked, or you'll have a tedious connectedness. Those things get out us no other option than writing a script that browses the website like a human would, clicking through jobs listings, without raising too many eyebrows on Glassdoor's servers.
It is annoying that a new Chrome window opens every time I run the script.
I totally hear you on that. Yous tin also let selenium do all the scraping in the background, without opening a browser window, although it might go tricky. This manner of scraping is called "headless". You lot demand to paste this code between your driver definition and driver.get and your script should do the scraping in the groundwork.
options.add_argument('headless')
Pros
Small-scale chance of getting caught past glassdoor and your http requests starting to getting rejected or throttled.
You are getting more data fields than Glassdoor's API. In fact, you are able to get even more if y'all extend the code for scraping the data points you are looking for.
Cons
This method is suitable if y'all are looking to scrape couple hundreds of jobs. For thousands, you might desire to get out your laptop overnight or take multiple jupyter notebooks do the scraping simultaneously, which gets messier since it increases the density of http requests to Glassdoor, which in turn, increases your IP accost to exist blocked.
THE End 🎉 🎊
Hope you enjoyed reading, cheers! 😊 👏
Source: https://mersakarya.medium.com/selenium-tutorial-scraping-glassdoor-com-in-10-minutes-3d0915c6d905